Modular Multiplicative Inverse
The modular multiplicative inverse of an integer a modulo m is an integer x such that

That is, it is the multiplicative inverse in the ring of integers modulo m. This is equivalent to
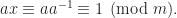
The multiplicative inverse of a modulo m exists if and only if a and m are coprime (i.e., if gcd(a, m) = 1).
Let’s see various ways to calculate Modular Multiplicative Inverse:
1. Brute Force
We can calculate the inverse using a brute force approach where we multiply a with all possible values x and find a x such that 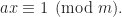
int modInverse(int a, int m) {
a %= m;
for(int x = 1; x < m; x++) {
if((a*x) % m == 1) return x;
}
}
The time complexity of the above codes is O(m).
2. Using Extended Euclidean Algorithm
We have to find a number x such that a·x = 1 (mod m). This can be written as well as a·x = 1 + m·y, which rearranges into a·x – m·y = 1. Since x and y need not be positive, we can write it as well in the standard form, a·x + m·y = 1.
In number theory, Bézout’s identity for two integers a, b is an expression ax + by = d, where x and y are integers (called Bézout coefficients for (a,b)), such that d is a common divisor of a and b. If d is the greatest common divisor of a and b then Bézout’s identity ax + by = gcd(a,b) can be solved using Extended Euclidean Algorithm.
The Extended Euclidean Algorithm is an extension to the Euclidean algorithm. Besides finding the greatest common divisor of integers a and b, as the Euclidean algorithm does, it also finds integers x and y (one of which is typically negative) that satisfy Bézout’s identity
ax + by = gcd(a,b). The Extended Euclidean Algorithm is particularly useful when a and b are coprime, since x is the multiplicative inverse of a modulo b, and y is the multiplicative inverse of b modulo a.
We will look at two ways to find the result of Extended Euclidean Algorithm.
Iterative Method
This method computes expressions of the form ri = axi + byi for the remainder in each step i of the Euclidean algorithm. Each successive number ri can be written as the remainder of the division of the previous two such numbers, which remainder can be expressed using the whole quotient qi of that division as follows:
By substitution, this gives:

The first two values are the initial arguments to the algorithm:
So the coefficients start out as x1 = 1, y1 = 0, x2 = 0, and y2 = 1, and the others are given by
The expression for the last non-zero remainder gives the desired results since this method computes every remainder in terms of a and b, as desired.


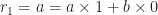

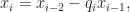
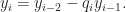
So the algorithm looks like,
- Apply Euclidean algorithm, and let qn(n starts from 1) be a finite list of quotients in the division.
- Initialize x0, x1 as 1, 0, and y0, y1 as 0,1 respectively.
- Then for each i so long as qi is defined,
- Compute xi+1 = xi-1 − qixi
- Compute yi+1 = yi-1 − qiyi
- Repeat the above after incrementing i by 1.
- The answers are the second-to-last of xn and yn.
/* This function return the gcd of a and b followed by
the pair x and y of equation ax + by = gcd(a,b)*/
pair<int, pair<int, int> > extendedEuclid(int a, int b) {
int x = 1, y = 0;
int xLast = 0, yLast = 1;
int q, r, m, n;
while(a != 0) {
q = b / a;
r = b % a;
m = xLast - q * x;
n = yLast - q * y;
xLast = x, yLast = y;
x = m, y = n;
b = a, a = r;
}
return make_pair(b, make_pair(xLast, yLast));
}
int modInverse(int a, int m) {
return (extendedEuclid(a,m).second.first + m) % m;
}
Recursive Method
This method attempts to solve the original equation directly, by reducing the dividend and divisor gradually, from the first line to the last line, which can then be substituted with trivial value and work backward to obtain the solution.
Notice that the equation remains unchanged after decomposing the original dividend in terms of the divisor plus a remainder, and then regrouping terms. So the algorithm looks like this:
- If b = 0, the algorithm ends, returning the solution x = 1, y = 0.
- Otherwise:
- Determine the quotient q and remainder r of dividing a by b using the integer division algorithm.
- Then recursively find coefficients s, t such that bs + rt divides both b and r.
- Finally the algorithm returns the solution x = t, and y = s − qt.
Here’s a C++ implementation:
/* This function return the gcd of a and b followed by
the pair x and y of equation ax + by = gcd(a,b)*/
pair<int, pair<int, int> > extendedEuclid(int a, int b) {
if(a == 0) return make_pair(b, make_pair(0, 1));
pair<int, pair<int, int> > p;
p = extendedEuclid(b % a, a);
return make_pair(p.first, make_pair(p.second.second - p.second.first*(b/a), p.second.first));
}
int modInverse(int a, int m) {
return (extendedEuclid(a,m).second.first + m) % m;
}
The time complexity of the above codes is O(log(m)2).
3. Using Fermat’s Little Theorem
Fermat’s little theorem states that if m is a prime and a is an integer co-prime to m, then ap − 1 will be evenly divisible by m. That is 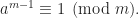
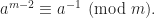
/* This function calculates (a^b)%MOD */
int pow(int a, int b, int MOD) {
int x = 1, y = a;
while(b > 0) {
if(b%2 == 1) {
x=(x*y);
if(x>MOD) x%=MOD;
}
y = (y*y);
if(y>MOD) y%=MOD;
b /= 2;
}
return x;
}
int modInverse(int a, int m) {
return pow(a,m-2,m);
}
The time complexity of the above codes is O(log(m)).
4. Using Euler’s Theorem
Fermat’s Little theorem can only be used if m is a prime. If m is not a prime we can use Euler’s Theorem, which is a generalization of Fermat’s Little theorem. According to Euler’s theorem, if a is coprime to m, that is, gcd(a, m) = 1, then 

Now lets take a little different question. Now suppose you have to calculate the inverse of first n numbers. From above the best we can do is O(n log(m)). Can we do any better? Yes.
We can use sieve to find a factor of composite numbers less than n. So for composite numbers inverse(i) = (inverse(i/factor(i)) * inverse(factor(i))) % m, and we can use either Extended Euclidean Algorithm or Fermat’s Theorem to find inverse for prime numbers. But we can still do better.
a * (m / a) + m % a = m
(a * (m / a) + m % a) mod m = m mod m, or
(a * (m / a) + m % a) mod m = 0, or
(- (m % a)) mod m = (a * (m / a)) mod m.
Dividing both sides by (a * (m % a)), we get
– inverse(a) mod m = ((m/a) * inverse(m % a)) mod m
inverse(a) mod m = (- (m/a) * inverse(m % a)) mod m
Here’s a sample C++ code:
vector<int> inverseArray(int n, int m) {
vector<int> modInverse(n + 1,0);
modInverse[1] = 1;
for(int i = 2; i <= n; i++) {
modInverse[i] = (-(m/i) * modInverse[m % i]) % m + m;
}
return modInverse;
}
The time complexity of the above code is O(n).
-fR0DDY
Share this:

Combination
In mathematics a combination is a way of selecting several things out of a larger group, where (unlike permutations) order does not matter. More formally a k-combination of a set S is a subset of k distinct elements of S. If the set has n elements the number of k-combinations is equal to the binomial coefficient. In this post we will see different methods to calculate the binomial.
1. Using Factorials
We can calculate nCr directly using the factorials.
nCr = n! / (r! * (n-r)!)
#include<iostream>
using namespace std;
long long C(int n, int r)
{
long long f[n + 1];
f[0]=1;
for (int i=1;i<=n;i++)
f[i]=i*f[i-1];
return f[n]/f[r]/f[n-r];
}
int main()
{
int n,r,m;
while (~scanf("%d%d",&n,&r))
{
printf("%lld\n",C(n, min(r,n-r)));
}
}
But this will work for only factorial below 20 in C++. For larger factorials you can either write big factorial library or use a language like Python. The time complexity is O(n).
If we have to calcuate nCr mod p(where p is a prime), we can calculate factorial mod p and then use modular inverse to find nCr mod p. If we have to find nCr mod m(where m is not prime), we can factorize m into primes and then use Chinese Remainder Theorem(CRT) to find nCr mod m.
#include<iostream>
using namespace std;
#include<vector>
/* This function calculates (a^b)%MOD */
long long pow(int a, int b, int MOD)
{
long long x=1,y=a;
while(b > 0)
{
if(b%2 == 1)
{
x=(x*y);
if(x>MOD) x%=MOD;
}
y = (y*y);
if(y>MOD) y%=MOD;
b /= 2;
}
return x;
}
/* Modular Multiplicative Inverse
Using Euler's Theorem
a^(phi(m)) = 1 (mod m)
a^(-1) = a^(m-2) (mod m) */
long long InverseEuler(int n, int MOD)
{
return pow(n,MOD-2,MOD);
}
long long C(int n, int r, int MOD)
{
vector<long long> f(n + 1,1);
for (int i=2; i<=n;i++)
f[i]= (f[i-1]*i) % MOD;
return (f[n]*((InverseEuler(f[r], MOD) * InverseEuler(f[n-r], MOD)) % MOD)) % MOD;
}
int main()
{
int n,r,p;
while (~scanf("%d%d%d",&n,&r,&p))
{
printf("%lld\n",C(n,r,p));
}
}
2. Using Recurrence Relation for nCr
The recurrence relation for nCr is C(i,k) = C(i-1,k-1) + C(i-1,k). Thus we can calculate nCr in time complexity O(n*r) and space complexity O(n*r).
#include<iostream>
using namespace std;
#include<vector>
/*
C(n,r) mod m
Using recurrence:
C(i,k) = C(i-1,k-1) + C(i-1,k)
Time Complexity: O(n*r)
Space Complexity: O(n*r)
*/
long long C(int n, int r, int MOD)
{
vector< vector<long long> > C(n+1,vector<long long> (r+1,0));
for (int i=0; i<=n; i++)
{
for (int k=0; k<=r && k<=i; k++)
if (k==0 || k==i)
C[i][k] = 1;
else
C[i][k] = (C[i-1][k-1] + C[i-1][k])%MOD;
}
return C[n][r];
}
int main()
{
int n,r,m;
while (~scanf("%d%d%d",&n,&r,&m))
{
printf("%lld\n",C(n, r, m));
}
}
We can easily reduce the space complexity of the above solution by just keeping track of the previous row as we don’t need the rest rows.
#include<iostream>
using namespace std;
#include<vector>
/*
Time Complexity: O(n*r)
Space Complexity: O(r)
*/
long long C(int n, int r, int MOD)
{
vector< vector<long long> > C(2,vector<long long> (r+1,0));
for (int i=0; i<=n; i++)
{
for (int k=0; k<=r && k<=i; k++)
if (k==0 || k==i)
C[i&1][k] = 1;
else
C[i&1][k] = (C[(i-1)&1][k-1] + C[(i-1)&1][k])%MOD;
}
return C[n&1][r];
}
int main()
{
int n,r,m,i,k;
while (~scanf("%d%d%d",&n,&r,&m))
{
printf("%lld\n",C(n, r, m));
}
}
3. Using expansion of nCr
Since
C(n,k) = n!/((n-k)!k!)
[n(n-1)...(n-k+1)][(n-k)...(1)]
= -------------------------------
[(n-k)...(1)][k(k-1)...(1)]
We can cancel the terms: [(n-k)…(1)] as they appear both on top and bottom, leaving:
n (n-1) (n-k+1)
- ----- ... -------
k (k-1) (1)
which we might write as:
C(n,k) = 1, if k = 0
= (n/k)*C(n-1, k-1), otherwise
#include<iostream>
using namespace std;
long long C(int n, int r)
{
if (r==0) return 1;
else return C(n-1,r-1) * n / r;
}
int main()
{
int n,r,m;
while (~scanf("%d%d",&n,&r))
{
printf("%lld\n",C(n, min(r,n-r)));
}
}
4. Using Matrix Multiplication
In the last post we learned how to use Fast Matrix Multiplication to calculate functions having linear equations in logarithmic time. Here we have the recurrence relation C(i,k) = C(i-1,k-1) + C(i-1,k).
If we take k=3 we can write,
C(i-1,1) + C(i-1,0) = C(i,1)
C(i-1,2) + C(i-1,1) = C(i,2)
C(i-1,3) + C(i-1,2) = C(i,3)
Now on the left side we have four variables C(i-1,0), C(i-1,1), C(i-1,2) and C(i-1,3).
On the right side we have three variables C(i,1), C(i,2) and C(i,3).
We need those two sets to be the same, except that the right side index numbers should be one higher than the left side index numbers. So we add C(i,0) on the right side. NOw let’s get our all important Matrix.
(. . . .) ( C(i-1,0) ) ( C(i,0) ) (. . . .) ( C(i-1,1) ) = ( C(i,1) ) (. . . .) ( C(i-1,2) ) ( C(i,2) ) (. . . .) ( C(i-1,3) ) ( C(i,3) )
The last three rows are trivial and can be filled from the recurrence equations above.
(. . . .) ( C(i-1,0) ) ( C(i,0) ) (1 1 0 0) ( C(i-1,1) ) = ( C(i,1) ) (0 1 1 0) ( C(i-1,2) ) ( C(i,2) ) (0 0 1 1) ( C(i-1,3) ) ( C(i,3) )
The first row, for C(i,0), depends on what is supposed to happen when k = 0. We know that C(i,0) = 1 for all i when k=0. So the matrix reduces to
(. . . .) ( C(i-1,0) ) ( C(i,0) ) (1 1 0 0) ( C(i-1,1) ) = ( C(i,1) ) (0 1 1 0) ( C(i-1,2) ) ( C(i,2) ) (0 0 1 1) ( C(i-1,3) ) ( C(i,3) )
And this then leads to the general form:
i
(. . . .) ( C(0,0) ) ( C(i,0) )
(1 1 0 0) ( C(0,1) ) = ( C(i,1) )
(0 1 1 0) ( C(0,2) ) ( C(i,2) )
(0 0 1 1) ( C(0,3) ) ( C(i,3) )
For example if we wan’t C(4,3) we just raise the above matrix to the 4th power.
4
(1 0 0 0) ( 1 ) ( 1 )
(1 1 0 0) ( 0 ) = ( 4 )
(0 1 1 0) ( 0 ) ( 6 )
(0 0 1 1) ( 0 ) ( 4 )
Here’s a C++ code.
#include<iostream>
using namespace std;
/*
C(n,r) mod m
Using Matrix Exponentiation
Time Complexity: O((r^3)*log(n))
Space Complexity: O(r*r)
*/
long long MOD;
template< class T >
class Matrix
{
public:
int m,n;
T *data;
Matrix( int m, int n );
Matrix( const Matrix< T > &matrix );
const Matrix< T > &operator=( const Matrix< T > &A );
const Matrix< T > operator*( const Matrix< T > &A );
const Matrix< T > operator^( int P );
~Matrix();
};
template< class T >
Matrix< T >::Matrix( int m, int n )
{
this->m = m;
this->n = n;
data = new T[m*n];
}
template< class T >
Matrix< T >::Matrix( const Matrix< T > &A )
{
this->m = A.m;
this->n = A.n;
data = new T[m*n];
for( int i = 0; i < m * n; i++ )
data[i] = A.data[i];
}
template< class T >
Matrix< T >::~Matrix()
{
delete [] data;
}
template< class T >
const Matrix< T > &Matrix< T >::operator=( const Matrix< T > &A )
{
if( &A != this )
{
delete [] data;
m = A.m;
n = A.n;
data = new T[m*n];
for( int i = 0; i < m * n; i++ )
data[i] = A.data[i];
}
return *this;
}
template< class T >
const Matrix< T > Matrix< T >::operator*( const Matrix< T > &A )
{
Matrix C( m, A.n );
for( int i = 0; i < m; ++i )
for( int j = 0; j < A.n; ++j )
{
C.data[i*C.n+j]=0;
for( int k = 0; k < n; ++k )
C.data[i*C.n+j] = (C.data[i*C.n+j] + (data[i*n+k]*A.data[k*A.n+j])%MOD)%MOD;
}
return C;
}
template< class T >
const Matrix< T > Matrix< T >::operator^( int P )
{
if( P == 1 ) return (*this);
if( P & 1 ) return (*this) * ((*this) ^ (P-1));
Matrix B = (*this) ^ (P/2);
return B*B;
}
long long C(int n, int r)
{
Matrix<long long> M(r+1,r+1);
for (int i=0;i<(r+1)*(r+1);i++)
M.data[i]=0;
M.data[0]=1;
for (int i=1;i<r+1;i++)
{
M.data[i*(r+1)+i-1]=1;
M.data[i*(r+1)+i]=1;
}
return (M^n).data[r*(r+1)];
}
int main()
{
int n,r;
while (~scanf("%d%d%lld",&n,&r,&MOD))
{
printf("%lld\n",C(n, r));
}
}
5. Using the power of prime p in n factorial
The power of prime p in n factorial is given by
εp = ⌊n/p⌋ + ⌊n/p2⌋ + ⌊n/p3⌋…
If we call the power of p in n factorial, the power of p in nCr is given by
e = countFact(n,i) – countFact(r,i) – countFact(n-r,i)
To get the result we multiply p^e for all p less than n.
#include<iostream>
using namespace std;
#include<vector>
/* This function calculates power of p in n! */
int countFact(int n, int p)
{
int k=0;
while (n>0)
{
k+=n/p;
n/=p;
}
return k;
}
/* This function calculates (a^b)%MOD */
long long pow(int a, int b, int MOD)
{
long long x=1,y=a;
while(b > 0)
{
if(b%2 == 1)
{
x=(x*y);
if(x>MOD) x%=MOD;
}
y = (y*y);
if(y>MOD) y%=MOD;
b /= 2;
}
return x;
}
long long C(int n, int r, int MOD)
{
long long res = 1;
vector<bool> isPrime(n+1,1);
for (int i=2; i<=n; i++)
if (isPrime[i])
{
for (int j=2*i; j<=n; j+=i)
isPrime[j]=0;
int k = countFact(n,i) - countFact(r,i) - countFact(n-r,i);
res = (res * pow(i, k, MOD)) % MOD;
}
return res;
}
int main()
{
int n,r,m;
while (scanf("%d%d%d",&n,&r,&m))
{
printf("%lld\n",C(n,r,m));
}
}
6. Using Lucas Theorem
For non-negative integers m and n and a prime p, the following congruence relation holds:
where
and
are the base p expansions of m and n respectively.
We only need to calculate nCr only for small numbers (less than equal to p) using any of the above methods.

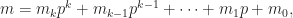

#include<iostream>
using namespace std;
#include<vector>
long long SmallC(int n, int r, int MOD)
{
vector< vector<long long> > C(2,vector<long long> (r+1,0));
for (int i=0; i<=n; i++)
{
for (int k=0; k<=r && k<=i; k++)
if (k==0 || k==i)
C[i&1][k] = 1;
else
C[i&1][k] = (C[(i-1)&1][k-1] + C[(i-1)&1][k])%MOD;
}
return C[n&1][r];
}
long long Lucas(int n, int m, int p)
{
if (n==0 && m==0) return 1;
int ni = n % p;
int mi = m % p;
if (mi>ni) return 0;
return Lucas(n/p, m/p, p) * SmallC(ni, mi, p);
}
long long C(int n, int r, int MOD)
{
return Lucas(n, r, MOD);
}
int main()
{
int n,r,p;
while (~scanf("%d%d%d",&n,&r,&p))
{
printf("%lld\n",C(n,r,p));
}
}
7. Using special n! mod p
We will calculate n factorial mod p and similarly inverse of r! mod p and (n-r)! mod p and multiply to find the result. But while calculating factorial mod p we remove all the multiples of p and write
n!* mod p = 1 * 2 * … * (p-1) * 1 * 2 * … * (p-1) * 2 * 1 * 2 * … * n.
We took the usual factorial, but excluded all factors of p (1 instead of p, 2 instead of 2p, and so on). Lets call this strange factorial.
So strange factorial is really several blocks of construction:
1 * 2 * 3 * … * (p-1) * i
where i is a 1-indexed index of block taken again without factors p.
The last block could be not full. More precisely, there will be floor(n/p) full blocks and some tail (its result we can compute easily, in O(P)).
The result in each block is multiplication 1 * 2 * … * (p-1), which is common to all blocks, and multiplication of all strange indices i from 1 to floor(n/p).
But multiplication of all strange indices is really a strange factorial again, so we can compute it recursively. Note, that in recursive calls n reduces exponentially, so this is rather fast algorithm.
Here’s the algorithm to calculate strange factorial.
int factMOD(int n, int MOD)
{
long long res = 1;
while (n > 1)
{
long long cur = 1;
for (int i=2; i<MOD; ++i)
cur = (cur * i) % MOD;
res = (res * powmod (cur, n/MOD, MOD)) % MOD;
for (int i=2; i<=n%MOD; ++i)
res = (res * i) % MOD;
n /= MOD;
}
return int (res % MOD);
}
But we can still reduce our complexity.
By Wilson’s Theorem, we know 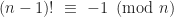
long long factMOD(int n, int MOD)
{
long long res = 1;
while (n > 1)
{
res = (res * pow(MOD - 1, n/MOD, MOD)) % MOD;
for (int i=2, j=n%MOD; i<=j; i++)
res = (res * i) % MOD;
n/=MOD;
}
return res;
}
Now in the above code we are calculating (-1)^(n/p). If (n/p) is even what we are multiplying by 1, so we can skip that. We only need to consider the case when (n/p) is odd, in which case we are multiplying result by (-1)%MOD, which ultimately is equal to MOD-res. SO our method again reduces to:
long long factMOD(int n, int MOD)
{
long long res = 1;
while (n > 0)
{
for (int i=2, m=n%MOD; i<=m; i++)
res = (res * i) % MOD;
if ((n/=MOD)%2 > 0)
res = MOD - res;
}
return res;
}
Finally the complete code here:
#include<iostream>
using namespace std;
#include<vector>
/* This function calculates power of p in n! */
int countFact(int n, int p)
{
int k=0;
while (n>=p)
{
k+=n/p;
n/=p;
}
return k;
}
/* This function calculates (a^b)%MOD */
long long pow(int a, int b, int MOD)
{
long long x=1,y=a;
while(b > 0)
{
if(b%2 == 1)
{
x=(x*y);
if(x>MOD) x%=MOD;
}
y = (y*y);
if(y>MOD) y%=MOD;
b /= 2;
}
return x;
}
/* Modular Multiplicative Inverse
Using Euler's Theorem
a^(phi(m)) = 1 (mod m)
a^(-1) = a^(m-2) (mod m) */
long long InverseEuler(int n, int MOD)
{
return pow(n,MOD-2,MOD);
}
long long factMOD(int n, int MOD)
{
long long res = 1;
while (n > 0)
{
for (int i=2, m=n%MOD; i<=m; i++)
res = (res * i) % MOD;
if ((n/=MOD)%2 > 0)
res = MOD - res;
}
return res;
}
long long C(int n, int r, int MOD)
{
if (countFact(n, MOD) > countFact(r, MOD) + countFact(n-r, MOD))
return 0;
return (factMOD(n, MOD) *
((InverseEuler(factMOD(r, MOD), MOD) *
InverseEuler(factMOD(n-r, MOD), MOD)) % MOD)) % MOD;
}
int main()
{
int n,r,p;
while (~scanf("%d%d%d",&n,&r,&p))
{
printf("%lld\n",C(n,r,p));
}
}
-fR0D
Share this:
Recurrence Relation and Matrix Exponentiation
Recurrence relations appear many times in computer science. Using recurrence relation and dynamic programming we can calculate the nth term in O(n) time. But many times we need to calculate the nth in O(log n) time. This is where Matrix Exponentiation comes to rescue.
We will specifically look at linear recurrences. A linear recurrence is a sequence of vectors defined by the equation Xi+1 = M Xi for some constant matrix M. So our aim is to find this constant matrix M, for a given recurrence relation.
Let’s first start by looking at the common structure of our three matrices Xi+1, Xi and M. For a recurrence relation where the next term is dependent on last k terms, Xi+1 and Xi+1 are matrices of size 1 x k and M is a matrix of size k x k.
| f(n+1) | | f(n) | | f(n) | | f(n-1) | | f(n-1) | = M x | f(n-2) | | ...... | | ...... | | f(n-k+1) | | f(n-k) |
Let’s look at different type of recurrence relations and how to find M.
1. Let’s start with the most common recurrence relation in computer science, The Fibonacci Sequence. Fi+1 = Fi + Fi-1.
| f(n+1) | = M x | f(n) | | f(n) | | f(n-1) |
Now we know that M is a 2 x 2 matrix. Let it be
| f(n+1) | = | a b | x | f(n) | | f(n) | | c d | | f(n-1) |
Now a*f(n) + b*f(n-1) = f(n+1) and c*f(n) + d*f(n-1) = f(n). Solving these two equations we get a=1,b=1,c=1 and d=0. So,
| f(n+1) | = | 1 1 | x | f(n) | | f(n) | | 1 0 | | f(n-1) |
2. For recurrence relation f(n) = a*f(n-1) + b*f(n-2) + c*f(n-3), we get
| f(n+1) | = | a b c | x | f(n) | | f(n) | | 1 0 0 | | f(n-1) | | f(n-1) | | 0 1 0 | | f(n-2) |
3. What if the recurrence relation is f(n) = a*f(n-1) + b*f(n-2) + c, where c is a constant. We can also add it in the matrices as a state.
| f(n+1) | = | a b 1 | x | f(n) | | f(n) | | 1 0 0 | | f(n-1) | | c | | 0 0 1 | | c |
4. If a recurrence relation is given like this f(n) = f(n-1) if n is odd, f(n-2) otherwise, we can convert it to f(n) = (n&1) * f(n-1) + (!(n&1)) * f(n-2) and substitute the value accordingly in the matrix.
5.If there are more than one recurrence relation, g(n) = a*g(n-1) + b*g(n-2) + c*f(n), and, f(n) = d*f(n-1) + e*f(n-2). We can still define the matrix X in following way
| g(n+1) | | a b c 0 | | g(n) | | g(n) | = | 1 0 0 0 | x | g(n-1) | | f(n+2) | | 0 0 d e | | f(n+1) | | f(n+1) | | 0 0 1 0 | | f(n) |
Now that we have got our matrix M, how are we going to find the nth term.
Xi+1 = M Xi
(Multiplying M both sides)
M * Xi+1 = M * M Xi
Xi+2 = M^2 Xi
..
Xi+k = M^k Xi
So all we need now is to find the matrix M^k to find the k-th term. For example in the case of Fibonacci Sequence,
M^2 = | 2 1 |
| 1 1 |
Hence F(2) = 2.
Now we need to learn to find M^k in O(n3 log b) time. The brute force approach to calculate a^b takes O(b) time, but using a recursive divide-and-conquer algorithm takes only O(log b) time:
- If b = 0, then the answer is 1.
- If b = 2k is even, then ab = (ak)2.
- If b is odd, then ab = a * ab-1.
We take a similar approach for Matrix Exponentiation. The multiplication part takes the O(n3) time and hence the overall complexity is O(n3 log b). Here’s a sample code in C++ using template class:
#include<iostream>
using namespace std;
template< class T >
class Matrix
{
public:
int m,n;
T *data;
Matrix( int m, int n );
Matrix( const Matrix< T > &matrix );
const Matrix< T > &operator=( const Matrix< T > &A );
const Matrix< T > operator*( const Matrix< T > &A );
const Matrix< T > operator^( int P );
~Matrix();
};
template< class T >
Matrix< T >::Matrix( int m, int n )
{
this->m = m;
this->n = n;
data = new T[m*n];
}
template< class T >
Matrix< T >::Matrix( const Matrix< T > &A )
{
this->m = A.m;
this->n = A.n;
data = new T[m*n];
for( int i = 0; i < m * n; i++ )
data[i] = A.data[i];
}
template< class T >
Matrix< T >::~Matrix()
{
delete [] data;
}
template< class T >
const Matrix< T > &Matrix< T >::operator=( const Matrix< T > &A )
{
if( &A != this )
{
delete [] data;
m = A.m;
n = A.n;
data = new T[m*n];
for( int i = 0; i < m * n; i++ )
data[i] = A.data[i];
}
return *this;
}
template< class T >
const Matrix< T > Matrix< T >::operator*( const Matrix< T > &A )
{
Matrix C( m, A.n );
for( int i = 0; i < m; ++i )
for( int j = 0; j < A.n; ++j )
{
C.data[i*C.n+j]=0;
for( int k = 0; k < n; ++k )
C.data[i*C.n+j] = C.data[i*C.n+j] + data[i*n+k]*A.data[k*A.n+j];
}
return C;
}
template< class T >
const Matrix< T > Matrix< T >::operator^( int P )
{
if( P == 1 ) return (*this);
if( P & 1 ) return (*this) * ((*this) ^ (P-1));
Matrix B = (*this) ^ (P/2);
return B*B;
}
int main()
{
Matrix<int> M(2,2);
M.data[0] = 1;M.data[1] = 1;
M.data[2] = 1;M.data[3] = 0;
int F[2]={0,1};
int N;
while (~scanf("%d",&N))
if (N>1)
printf("%lld\n",(M^N).data[0]);
else
printf("%d\n",F[N]);
}
Share this:
Pollard Rho Brent Integer Factorization
Pollard Rho is an integer factorization algorithm, which is quite fast for large numbers. It is based on Floyd’s cycle-finding algorithm and on the observation that two numbers x and y are congruent modulo p with probability 0.5 after 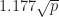
Algorithm Input : A number N to be factorized Output : A divisor of N If x mod 2 is 0 return 2 Choose random x and c y = x g = 1 while g=1 x = f(x) y = f(f(y)) g = gcd(x-y,N) return g
Note that this algorithm may not find the factors and will return failure for composite n. In that case, use a different f(x) and try again. Note, as well, that this algorithm does not work when n is a prime number, since, in this case, d will be always 1. We choose f(x) = x*x + c. Here’s a python implementation :
def pollardRho(N):
if N%2==0:
return 2
x = random.randint(1, N-1)
y = x
c = random.randint(1, N-1)
g = 1
while g==1:
x = ((x*x)%N+c)%N
y = ((y*y)%N+c)%N
y = ((y*y)%N+c)%N
g = gcd(abs(x-y),N)
return g
In 1980, Richard Brent published a faster variant of the rho algorithm. He used the same core ideas as Pollard but a different method of cycle detection, replacing Floyd’s cycle-finding algorithm with the related Brent’s cycle finding method. It is quite faster than pollard rho. Here’s a python implementation :
def brent(N):
if N%2==0:
return 2
y,c,m = random.randint(1, N-1),random.randint(1, N-1),random.randint(1, N-1)
g,r,q = 1,1,1
while g==1:
x = y
for i in range(r):
y = ((y*y)%N+c)%N
k = 0
while (k<r and g==1):
ys = y
for i in range(min(m,r-k)):
y = ((y*y)%N+c)%N
q = q*(abs(x-y))%N
g = gcd(q,N)
k = k + m
r = r*2
if g==N:
while True:
ys = ((ys*ys)%N+c)%N
g = gcd(abs(x-ys),N)
if g>1:
break
return g
-fR0DDY
Share this:
Miller Rabin Primality Test
Miller Rabin Primality Test is a probabilistic test to check whether a number is a prime or not. It relies on an equality or set of equalities that hold true for prime values, then checks whether or not they hold for a number that we want to test for primality.
Theory
1> Fermat’s little theorem states that if p is a prime and 1 ≤ a < p then
2> If p is a prime and 


3> If n is an odd prime then n-1 is an even number and can be written as 
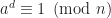

4> The Miller–Rabin primality test is based on the contrapositive of the above claim. That is, if we can find an a such that 
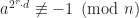
5> We test our number N for some random a and either declare that N is definitely a composite or probably a prime. The probably that a composite number is returned as prime after k itereations is
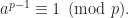
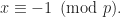

Algorithm
Input :A number N to be tested and a variable iteration-the number of 'a' for which algorithm will test N. Output :0 if N is definitely a composite and 1 if N is probably a prime. Write N asmod n if x =1 or x = n-1 Next iteration for r = 1 to s-1 x =
mod n if x = 1 return false if x = N-1 Next iteration return false return true
Here’s a python implementation :
import random
def modulo(a,b,c):
x = 1
y = a
while b>0:
if b%2==1:
x = (x*y)%c
y = (y*y)%c
b = b/2
return x%c
def millerRabin(N,iteration):
if N<2:
return False
if N!=2 and N%2==0:
return False
d=N-1
while d%2==0:
d = d/2
for i in range(iteration):
a = random.randint(1, N-1)
temp = d
x = modulo(a,temp,N)
while (temp!=N-1 and x!=1 and x!=N-1):
x = (x*x)%N
temp = temp*2
if (x!=N-1 and temp%2==0):
return False
return True
-fR0DDY
Share this:
Knuth–Morris–Pratt Algorithm (KMP)
Knuth–Morris–Pratt algorithm is the most popular linear time algorithm for string matching. It is little difficult to understand and debug in real time contests. So most programmer’s have a precoded KMP in their kitty.
To understand the algorithm, you can either read it from Introduction to Algorithms (CLRS) or from the wikipedia page. Here’s a sample C++ code.
void preKMP(string pattern, int f[])
{
int m = pattern.length(),k;
f[0] = -1;
for (int i = 1; i<m; i++)
{
k = f[i-1];
while (k>=0)
{
if (pattern[k]==pattern[i-1])
break;
else
k = f[k];
}
f[i] = k + 1;
}
}
bool KMP(string pattern, string target)
{
int m = pattern.length();
int n = target.length();
int f[m];
preKMP(pattern, f);
int i = 0;
int k = 0;
while (i<n)
{
if (k==-1)
{
i++;
k = 0;
}
else if (target[i]==pattern[k])
{
i++;
k++;
if (k==m)
return 1;
}
else
k=f[k];
}
return 0;
}
NJOY!
-fR0DDY
Share this:
The Z Algorithm
In this post we will discuss an algorithm for linear time string matching. It is easy to understand and code and is usefull in contests where you cannot copy paste code.
Let our string be denoted by S.
z[i] denotes the length of the longest substring of S that starts at i and is a prefix of S.
α denotes the substring.
r denotes the index of the last character of α and l denotes the left end of α.
To find whether a pattern(P) of length n is present in a target string(T) of length m, we will create a new string S = P$T where $ is a character present neither in P nor in T. The space taken is n+m+1 or O(m). We will compute z[i] for all i such that 0 < i < n+m+1. If z[i] is equal to n then we have found a occurrence of P at position i – n – 1. So we can all the occurrence of P in T in O(m) time. To calculate z[i] we will use the z algorithm.
The Z Algorithm can be read from the section 1.3-1.5 of book Algorithms on strings, trees, and sequences by Gusfield. Here is a sample C++ code.
bool zAlgorithm(string pattern, string target)
{
string s = pattern + '$' + target ;
int n = s.length();
vector<int> z(n,0);
int goal = pattern.length();
int r = 0, l = 0, i;
for (int k = 1; k<n; k++)
{
if (k>r)
{
for (i = k; i<n && s[i]==s[i-k]; i++);
if (i>k)
{
z[k] = i - k;
l = k;
r = i - 1;
}
}
else
{
int kt = k - l, b = r - k + 1;
if (z[kt]>b)
{
for (i = r + 1; i<n && s[i]==s[i-k]; i++);
z[k] = i - k;
l = k;
r = i - 1;
}
}
if (z[k]==goal)
return true;
}
return false;
}
NJOY!
-fR0D
Share this:
All Pair Shortest Path (APSP)
Question : Find shortest paths between all pairs of vertices in a graph.
Floyd-Warshall Algorithm
It is one of the easiest algorithms, and just involves simple dynamic programming. The algorithm can be read from this wikipedia page.
#define SIZE 31
#define INF 1e8
double dis[SIZE][SIZE];
void init(int N)
{
for (k=0;k<N;k++)
for (i=0;i<N;i++)
dis[i][j]=INF;
}
void floyd_warshall(int N)
{
int i,j,k;
for (k=0;k<N;k++)
for (i=0;i<N;i++)
for (j=0;j<N;j++)
dis[i][j]=min(dis[i][j],dis[i][k]+dis[k][j]);
}
int main()
{
//input size N
init(N);
//set values for dis[i][j]
floyd_warshall(N);
}
We can also use the algorithm to
- find the shortest path
- we can use another matrix called predecessor matrix to construct the shortest path.
- find negative cycles in a graph.
- If the value of any of the diagonal elements is less than zero after calling the floyd-warshall algorithm then there is a negative cycle in the graph.
- find transitive closure
- to find if there is a path between two vertices we can use a boolean matrix and use and-& and or-| operators in the floyd_warshall algorithm.
- to find the number of paths between any two vertices we can use a similar algorithm.
NJOY!!
-fR0DDY
Share this:
Number of Cycles in a Graph
Question : Find the number of simple cycles in a simple graph.
Simple Graph – An undirected graph that has no loops and no more than one edge between any two different vertices.
Simple Cycle – A closed (simple) path, with no other repeated vertices or edges other than the starting and ending vertices.
Given a graph of N vertices and M edges, we will look at an algorithm with time complexity O(2NN2). We will use dynamic programming to do so. Let there be a matrix map, such that map[i][j] is equal to 1 if there is a edge between i and j and 0 otherwise. Let there be another array f[1<<N][N] which denotes the number of simple paths.
Let, i denote a subset S of our vertices k be the smallest set bit of i then f[i][j] is the number of simple paths from j to k that contains vertices only from the set S.
In our algorithm first we will find f[i][j] and then check if there is a edge between k and j, if yes, we can complete every simple path from j to k into a simple cycle and hence we add f[i][j] to our result of total number of simple cycles.Now how to find f[i][j].
For very subset i we iterate through all edges j. Once we have set k, we look for all vertices 'l' that can be neighbors of j in our subset S. So if l is a vertex in subset S and there is edge from j to l then f[i][j] = f[i][j] + the number of simple paths from l to i in the subset {S – j}. Since a simple graph is undirected or bidirectional, we have counted every cycle twice and so we divide our result by 2. Here's a sample C++ code which takes N, M and the edges as input.
#include<iostream>
using namespace std;
#define SIZE 20
bool map[SIZE][SIZE],F;
long long f[1<<SIZE][SIZE],res=0;
int main()
{
int n,m,i,j,k,l,x,y;
scanf("%d%d",&n,&m);
for (i=0;i<m;i++)
{
scanf("%d%d",&x,&y);
x--;y--;
if (x>y)
swap(x,y);
map[x][y]=map[y][x]=1;
f[(1<<x)+(1<<y)][y]=1;
}
for (i=7;i<(1<<n);i++)
{
F=1;
for (j=0;j<n;j++)
if (i&(1<<j) && f[i][j]==0)
{
if (F)
{
F=0;
k=j;
continue;
}
for (l=k+1;l<n;l++)
{
if (i&(1<<l) && map[j][l])
f[i][j]+=f[i-(1<<j)][l];
}
if (map[k][j])
res+=f[i][j];
}
}
printf("%lld\n",res/2);
}
NJOY!
-fR0DDY
Share this:
Longest Common Increasing Subsequence (LCIS)
Given 2 sequences of integers, we need to find a longest sub-sequence which is common to both the sequences, and the numbers of such a sub-sequence are in strictly increasing order.
For example,
2 3 1 6 5 4 6
1 3 5 6
the LCIS is 3 5 6.
The sequence a1, a2, …, an is called increasing, if ai<ai+1 for i<n.The sequence s1, s2, …, sk is called the subsequence of the sequence a1, a2, …, an, if there exist such a set of indexes 1 ≤ i1 < i2 < … < ik ≤ n that aij = sj. In other words, the sequence s can be derived from the sequence a by crossing out some elements.
A nice tutorial on the algorithm is given on CodeChef blog here. If you read the blog you can see that instead of looking for LCIS in a candidate matrix, we can keep an array that stores the length of LCIS ending at that particular element. Also we keep a lookup previous array that gives the index of the previous element of the LCIS, which is used to reconstruct the LCIS.
For every element in the two arrays
1> If they are equal we check whether the LCIS formed will be bigger than any previous such LCIS ending at that element. If yes we change the data.
2> If the jth element of array B is smaller than ith element of array A, we check whether it has a LCIS greater than current LCIS length, if yes we store it as previous value and it’s LCIS length as current LCIS length.
Here’s a C++ code.
#include<iostream>
using namespace std;
#include<vector>
void LCIS(vector<int> A, vector<int> B)
{
int N=A.size(),M=B.size(),i,j;
vector<int> C(M,0);
vector<int> prev(M,0);
vector<int> res;
for (i=0;i<N;i++)
{
int cur=0,last=-1;
for (j=0;j<M;j++)
{
if (A[i]==B[j] && cur+1>C[j])
{
C[j]=cur+1;
prev[j]=last;
}
if (B[j]<A[i] && cur<C[j])
{
cur=C[j];
last=j;
}
}
}
int length=0,index=-1;
for (i=0;i<M;i++)
if (C[i]>length)
{
length=C[i];
index=i;
}
printf("The length of LCIS is %d\n",length);
if (length>0)
{
printf("The LCIS is \n");
while (index!=-1)
{
res.push_back(B[index]);
index=prev[index];
}
reverse(res.begin(),res.end());
for (i=0;i<length;i++)
printf("%d%s",res[i],i==length-1?"\n":" ");
}
}
int main()
{
int n,m,i;
scanf ("%d", &n);
vector<int> A(n,0);
for (i = 0; i < n; i++)
scanf ("%d", &A[i]);
scanf ("%d", &m);
vector<int> B(m,0);
for (i = 0; i < m; i++)
scanf ("%d", &B[i]);
LCIS(A,B);
}
NJOY!
-fR0DDY



